这篇文章是从 AsyncTask 的角度进入,从而分析线程和线程池的文章.
涉及到一下内容.
- AsyncTask 的使用
- AsyncTask 的源码分析
- 线程
- Thread
- Runnable
- Callable
- FutureTask
- Future
- 线程池Executor
- ThreadPoolExecutor
- FixedThreadPool
- CachedThreadPool
- ScheduledThreadPool
- SingleThreadPool
通过一个模拟下载文件的例子来看.
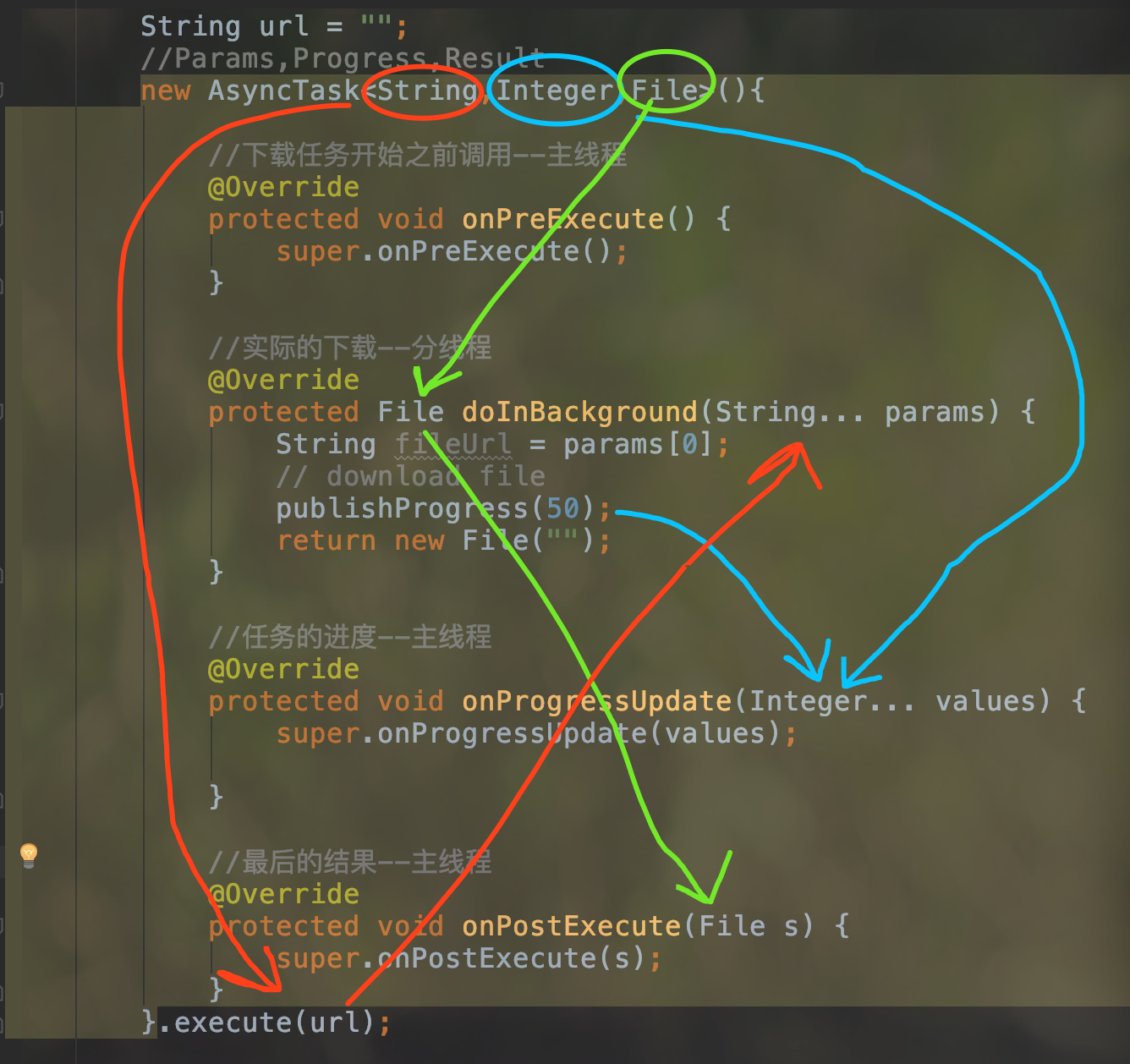
String url = "";
//Params,Progress,Result
new AsyncTask<String,Integer,File>(){
//下载任务开始之前调用--主线程
@Override
protected void onPreExecute() {
super.onPreExecute();
}
//实际的下载--分线程
@Override
protected File doInBackground(String... params) {
String fileUrl = params[0];
// download file
publishProgress(50);
return new File("");
}
//任务的进度--主线程
@Override
protected void onProgressUpdate(Integer... values) {
super.onProgressUpdate(values);
}
//最后的结果--主线程
@Override
protected void onPostExecute(File s) {
super.onPostExecute(s);
}
}.execute(url);
其实 AsyncTask 的使用无外乎就四个方法而已.
onPreExecute() 在任务开始之前调用–主线程
doInBackground(String... params) 实际的任务–分线程
onProgressUpdate(Integer... values) 任务的进度–主线程
onPostExecute(File s) 最后的结果–主线程
至于 AsyncTask的三个泛型参数
第一个是传入的参数类型
第二个是进度的类型
第三个是结果得类型
通过一个图看明白这三个参数
上面我们知道的 AsyncTask 的使用,我们来看看它的源码.
从入口的方法 execute() 开始
@MainThread
public final AsyncTask<Params, Progress, Result> execute(Params... params) {
return executeOnExecutor(sDefaultExecutor, params);
}
其实走的是executeOnExecutor(sDefaultExecutor, params)这个方法
@MainThread
public final AsyncTask<Params, Progress, Result> executeOnExecutor(Executor exec,
Params... params) {
if (mStatus != Status.PENDING) {
switch (mStatus) {
case RUNNING:
throw new IllegalStateException("Cannot execute task:"
+ " the task is already running.");
case FINISHED:
throw new IllegalStateException("Cannot execute task:"
+ " the task has already been executed "
+ "(a task can be executed only once)");
}
}
mStatus = Status.RUNNING;
onPreExecute();
mWorker.mParams = params;
exec.execute(mFuture);
return this;
}
这个方法首先进行了一个状态的判断,随后将状态更改为RUNNING.
紧接着就调用了 onPreExecute() 这个方法.
随后是这句 mWorker.mParams = params , 就是将我们传进来的参数放进了mWorker.mParams.
那么mWorker 是什么呢?
private static abstract class WorkerRunnable<Params, Result> implements Callable<Result> {
Params[] mParams;
}
跟踪看到其实 mWorker 本质上是 Callable<V> , 它是一个接口.
public interface Callable<V> {
V call() throws Exception;
}
那么Callable到底是个什么呢? 要说清楚它,我们要先回顾下 Java 中的线程.
线程一般实现线程的方式是两种
1.Threadclass MyThread extend Thread(){
@Override
public void run() {
super.run();
Log.e("Cml",Thread.currentThread().getId());
}
}
new MyThread().start();
class MyThread implements Runnable{
@Override
public void run() {
Log.i("MyThread", Thread.currentThread().getName());
}
}
MyThreaed myThread = new MyThread();
new Thread(myThread).start();
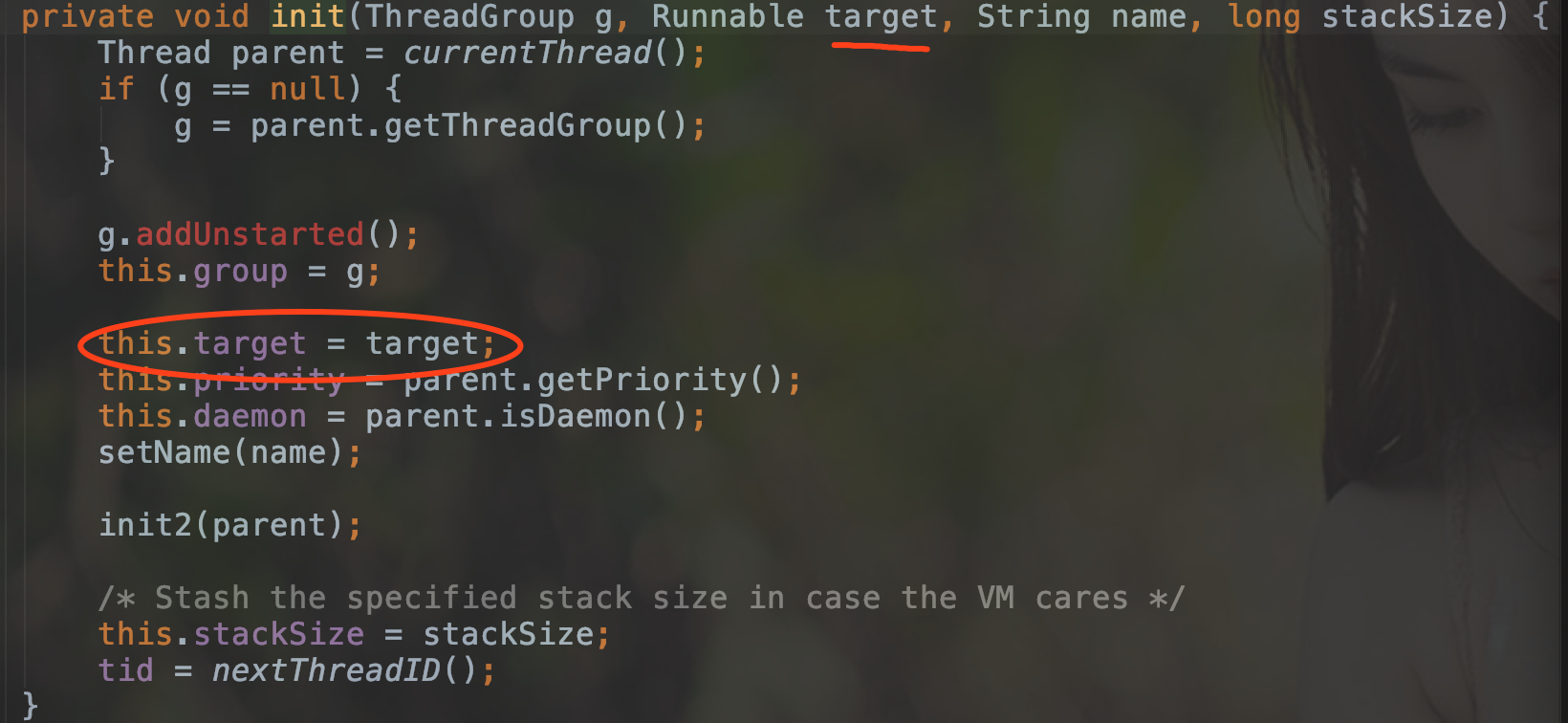
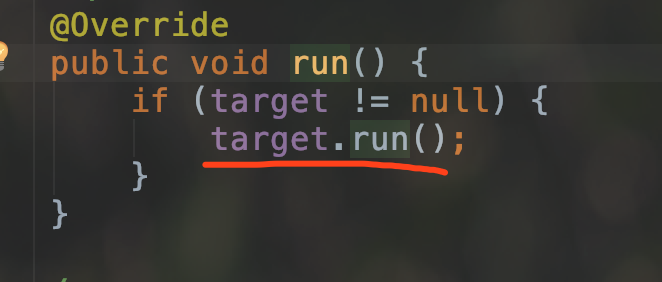
这里看一下 Runnable , 其本质是一个接口,跟线程没什么关系.但是为什么它又能运行在新线程上呢?其实是 Thread 调用 Runnable 的 run 方法 , 从而达到 Runnable 的 run 在新线程中运行的目的.
这一点可以在 Thread 的源码中提现出来.

好了,回到我们的 Callable .回顾完 Runnable 后 , 就好理解 Callable 了.
其实 Callable 就是 Runnable 的加强版而已. 对比看一下

是不是相当于 Runnable + 泛型 + Exception + 带返回值的 run 方法 == Callable
没错就是这样.
只不过 Runnable 是在JDK1.0就有了,而 Callable是在 JDK1.5中才增加的.
但是由于 Thread 只支持 Runnable 接口,放着Callable 这么好的东西不能用.
FutureTask所以就引入了 FutureTask
public class FutureTask<V> implements RunnableFuture<V> {
//.... 此处省略类中的代码
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
//.... 此处省略类中的代码
}
然后看看 RunnableFuture
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
接着看看 Future
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
通过上面的三段代码我们可以分析得到.
- FutureTask 是为了弥补 Thread 的不足而设计的
- FutureTask 兼顾了 Runnable 和 Future 两者的优点,所以可以准确的知道线程的完成情况和完成后的返回结果同时还可以取消异步计算
- FutureTask 内部是使用 Callable 实现的
所以我们弄明白了Callable之后,我们也就知道了 mWorker 相当于一个线程.事实也确实如此.
看一下mWorker的初始化就知道了(在 AsyncTask 的构造方法中).
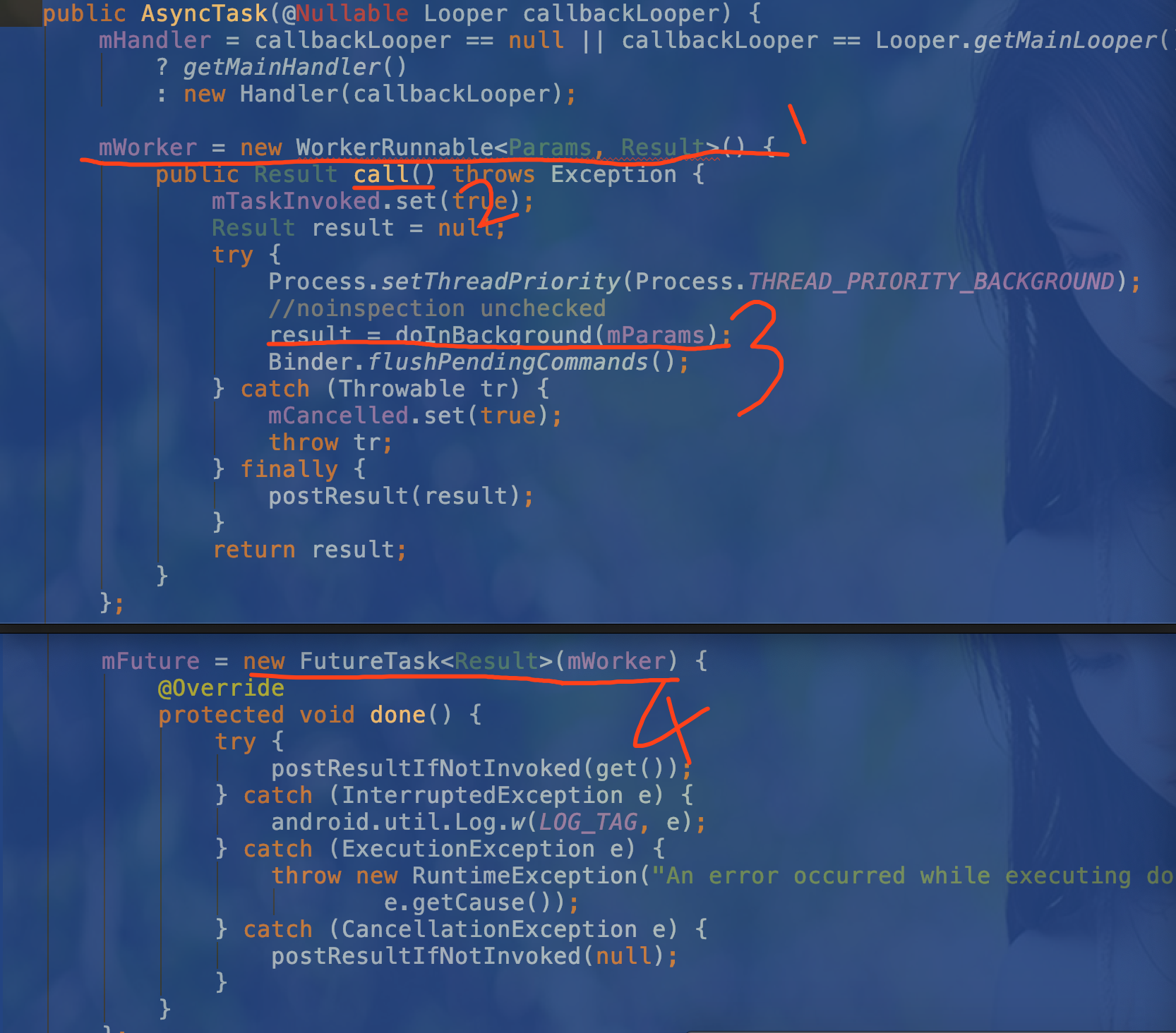
标记1: 我们前面看过WorkerRunnable实际上是 Callable
标记2: call()方法相当于 Runnable 的 run() 方法是实际运行在线程中的
标记3 我们 AsyncTask 的 doInBackground() 运行在 call()中,这也叫解释了为什么 doInBackground 是运行在新线程的.
标记4 将 WorkerRunnable 也就是 Callable 放进了 FutureTask(相当于 Thread) 中,就可以保证 call() 运行在新线程中了.
至此我们其实才弄明白了
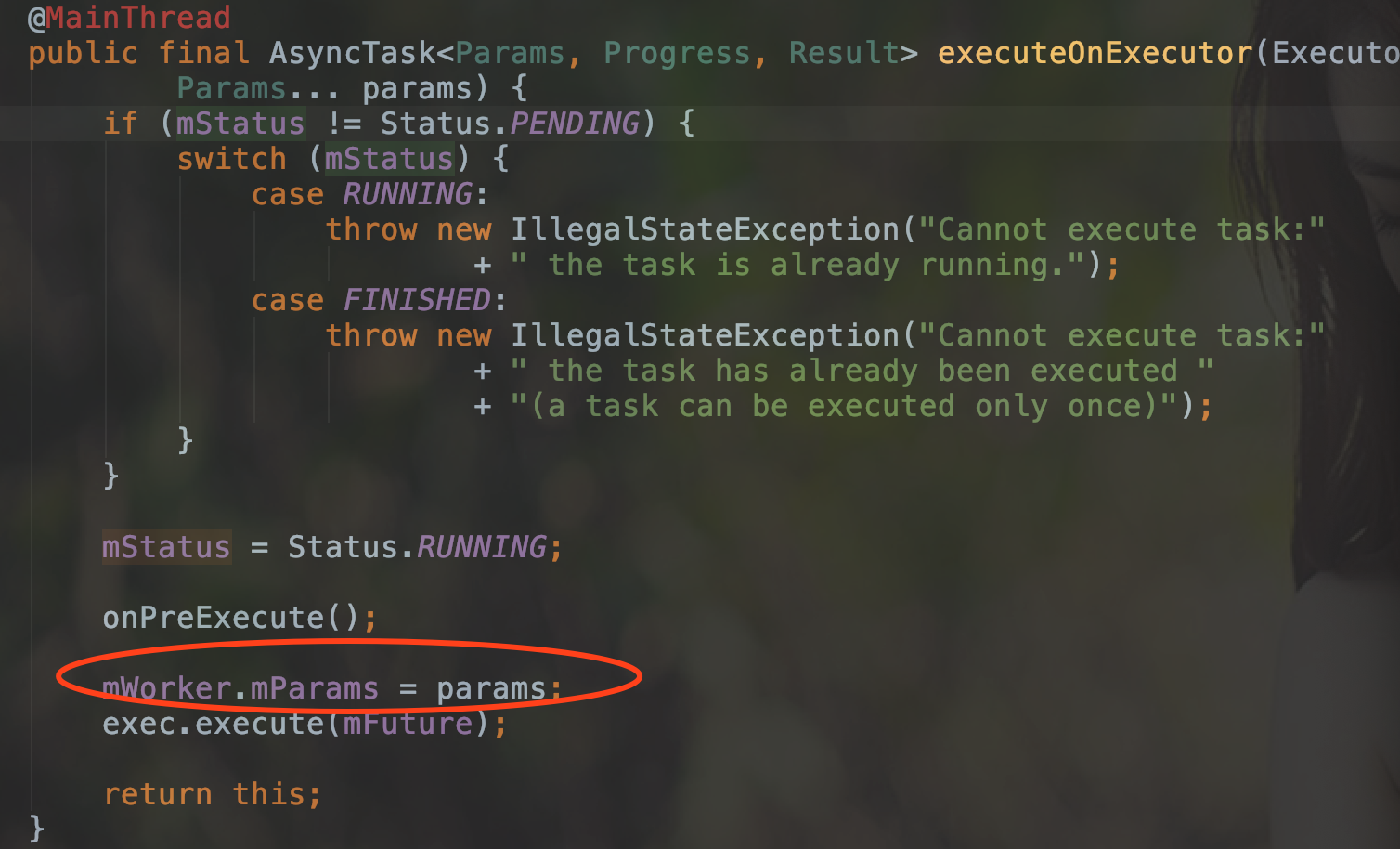
这个方法中红色圆圈的那句话而已.
我们继续往下走看 exec.execute(mFuture);
我们先看我们熟悉的 mFuture 解释 上上个图中注释4处的FutureTask, 而它被当做参入传进了 exec 的 exectue()的方法中.
那么 exec 是什么鬼?
跟踪一下看到 exec 其实是 sDefaultExecutor .
接着看
private static volatile Executor sDefaultExecutor = SERIAL_EXECUTOR;
public static final Executor SERIAL_EXECUTOR = new SerialExecutor();
private static class SerialExecutor implements Executor {
final ArrayDeque<Runnable> mTasks = new ArrayDeque<Runnable>();
Runnable mActive;
public synchronized void execute(final Runnable r) {
mTasks.offer(new Runnable() {
public void run() {
try {
r.run();
} finally {
scheduleNext();
}
}
});
if (mActive == null) {
scheduleNext();
}
}
protected synchronized void scheduleNext() {
if ((mActive = mTasks.poll()) != null) {
THREAD_POOL_EXECUTOR.execute(mActive);
}
}
}
所以最后跟踪下来发现exec其实就是Executor.
Executor又是什么呢?
其实可以说它就是线程池.
因为 Android 中的线程池的概念来源就是 Java 中的 Executor ,它本质只是一个接口.
因此 Android 中真正的线程池实现为 ThreadPoolExecutor .
既然知道了这些,那么exec就可以说是一个线程池.
回到 exec.execute(mFuture) 其实就是将任务放进了线程池而已.
你看看execute() 的实际实现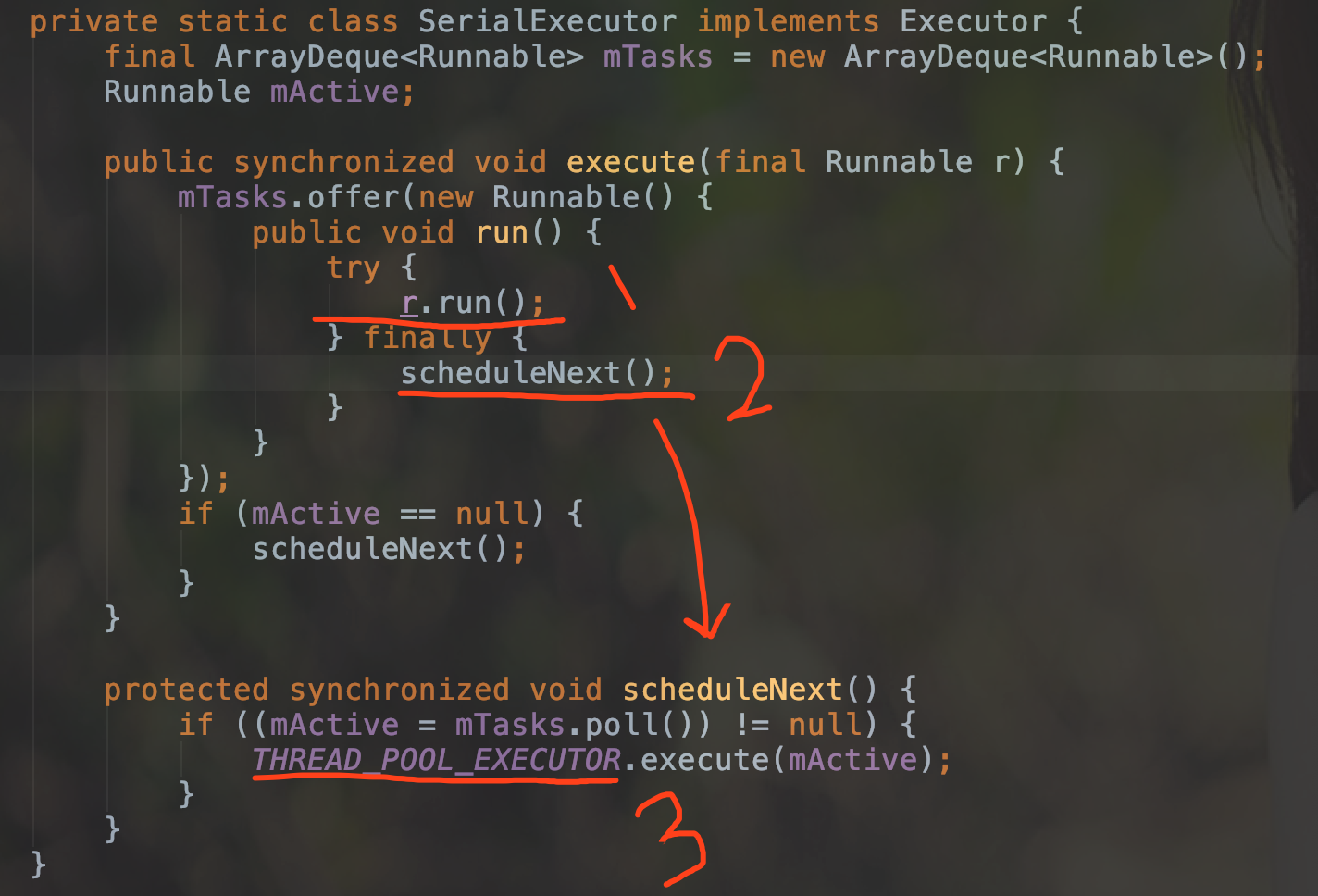
注释1 线程的 run
注释2 和 注释3 结合起来你就发现实际的执行操作是在THREAD_POOL_EXECUTOR也就是ThreadPoolExecutor这个线程池中的.
而且你还会发现实际上 SerialExecutor 这个线程池实际上做的工作时保证任务的顺序执行.
所以得到一个结论就是即使你多次的调用 AsyncTask 的 execute() 来传递了多个任务,它们还是顺序执行的.
如这样:
new AsyncTask().execute("");
new AsyncTask().execute("");
new AsyncTask().execute("");
...
Tips: 其实在 Android3.0之前 AsyncTask 确实是并发执行的.只不过从 Android3.0开始为了避免 AsyncTask所带来的并发错误, 从而将 AsyncTask 更改为了串行执行.
如果确实想要 AsyncTask 并发执行,我们通过分析源码也可以得到一个方法,就是同时调用executeOnExecutor()来进行,跳过用来保证顺序的线程池sDefaultExecutor,就可以实现了.
如这样 : (就可以实现并发执行在 Android3.0之后)
new AsyncTask<>().executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR,"");
new AsyncTask<>().executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR,"");
new AsyncTask<>().executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR,"");
...
接下来我们就看看 Android 中的线程池也就是ThreadPoolExecutor
我们已经知道了ThreadPoolExecutor是线程池Executor的真正实现,so就看看它的庐山真面目吧.
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//... 此处省略构造器内部的代码
}
来看看构造器中的这么多参数都是干什么的
corePoolSize : 线程的核心线程数
核心线程的终止条件:
- 默认情况,核心线程会一直存活,即使其处于闲置状态
- 当 ThreadPoolExecutor 的 allowCoreThreadTimeOut 属性为 true 时 , 如果核心线程的等待时间超过 keepAliveTime 所指定的时间 , 那么核心线程就会被终止.
maximumPoolSize : 最大线程数(核心线程+非核心线程)
当线程数量超过最大线程数量的时候,后续的新任务将会被阻塞.
keepAliveTime : 线程的超时时长
默认情况下也就是allowCoreThreadTimeOut为 false 的时候,keepAliveTime 指定的是非核心线程的超时时长.
当allowCoreThreadTimeOut为 true 的时候,那么核心线程的超时时间也会同时由它来控制.
unit : keepAliveTime所指定时间的单位
workQueue
是线程池中的任务队列,通过线程池的execute()方法传递进来的 Runnable 对象会被存储在这个参数中.
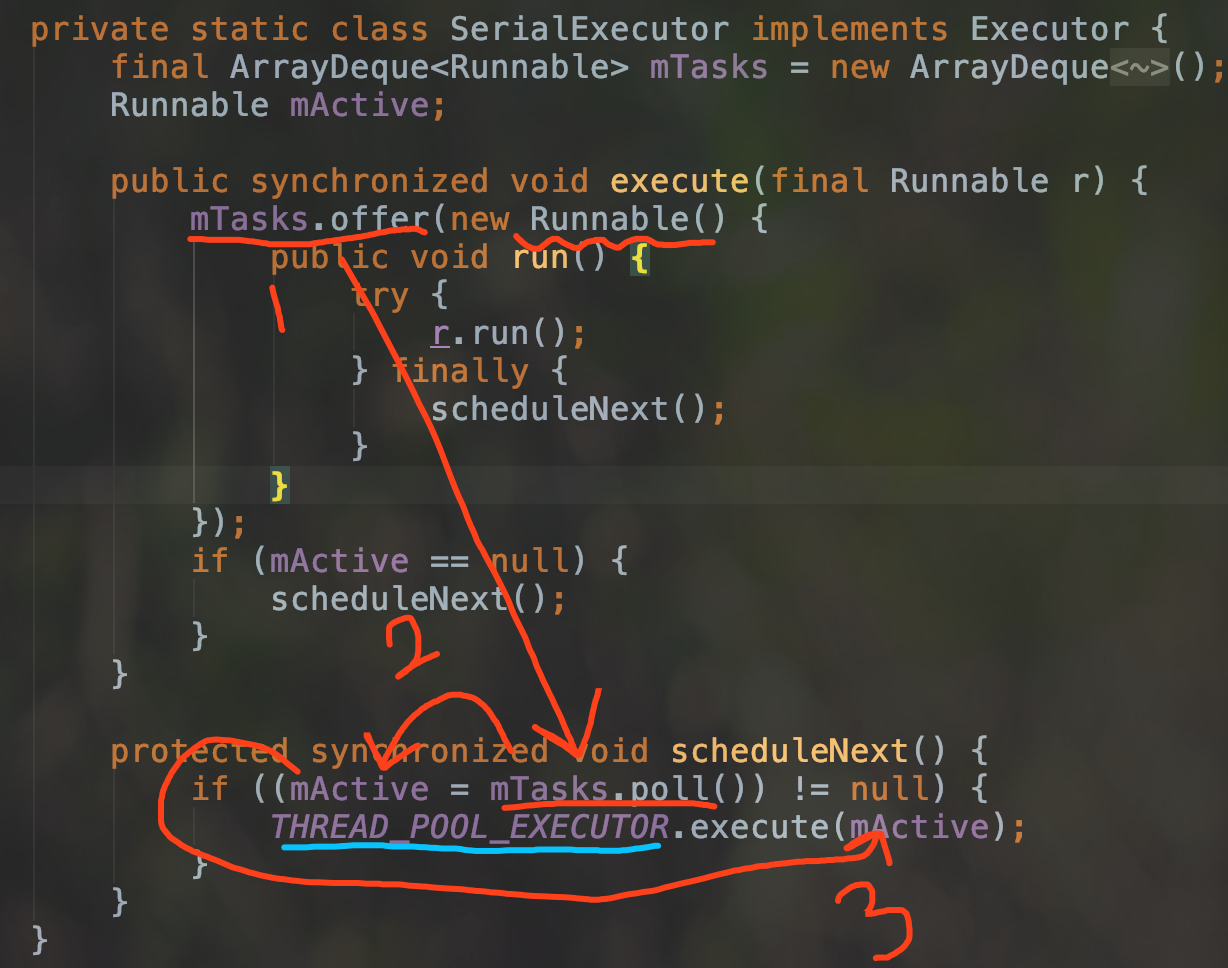
看看 AsyncTask 中的 SerialExecutor 线程池通过如图的3步将 Runnable 对象传递到了 ThreadPoolExecutor 线程池中. 所以我们说 AsyncTask 的实际执行是在 ThreadPoolExecutor 线程池中.
threadFactory : 线程工厂
顾名思义,为线程池提供了创建新线程的功能.
handler : 用来通知调用者的(不常用)
当线程池无法执行新任务时(任务队列已满或无法成功执行任务),会调用 handler 的rejectedExecution()方法来通知调用者,默认情况下,会直接抛出RejectedExecutionException异常.
但是ThreadPoolExecutor为RejectedExecutionHandler 提供了四种可选项如下:
- AbortPolicy (默认)
- CallerRunsPolicy
- DiscardPolicy
- DiscardOldestPolicy
总结一下,ThreadPoolExecutor 的执行规则
- 若线程中的线程数量未达到核心线程的数量,那么直接启动一个核心线程来执行任务
- 若线程数量大于或等于核心线程,那么任务会被插入任务队列中等待
- 若任务队列已经满了的情况下,若线程数量未达到线程池规定的最大值,那么会启动一个非核心线程来执行任务
- 若任务队列已经满了,并且线程数量也达到了线程池规定的最大值,那么就拒绝执行此任务同时调用RejectedExecutionHandler 的 rejectedExecution()方法来通知调用者.
好了,既然我们了解了 ThreadPoolExecutor ,并且也知道了AsyncTask 的实际执行确实是在 ThreadPoolExecutor 中.那么我们也看看 ThreadPoolExecutor 在 AsyncTask 中的初始化的时候传递的参数吧.
static {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE_SECONDS, TimeUnit.SECONDS,
sPoolWorkQueue, sThreadFactory);
threadPoolExecutor.allowCoreThreadTimeOut(true);
THREAD_POOL_EXECUTOR = threadPoolExecutor;
}
可以看到初始化是在一个静态的代码块中进行的,那么我们来看下参数都是怎么传的吧.
private static final int CORE_POOL_SIZE = Math.max(2, Math.min(CPU_COUNT - 1, 4));
private static final int MAXIMUM_POOL_SIZE = CPU_COUNT * 2 + 1;
private static final int KEEP_ALIVE_SECONDS = 30;
通过上面的代码了解到
- 核心线程跟 cpu 的数量有关系
- 最大线程数是 cpu 数量的2倍 + 1
- allowCoreThreadTimeOut 被设置为了 true,也就是允许核心线程被终止
- 线程的超时时间是30s
好了,在新线程中执行完了,是怎么切换到主线程的呢.我们之前看到过这部分代码
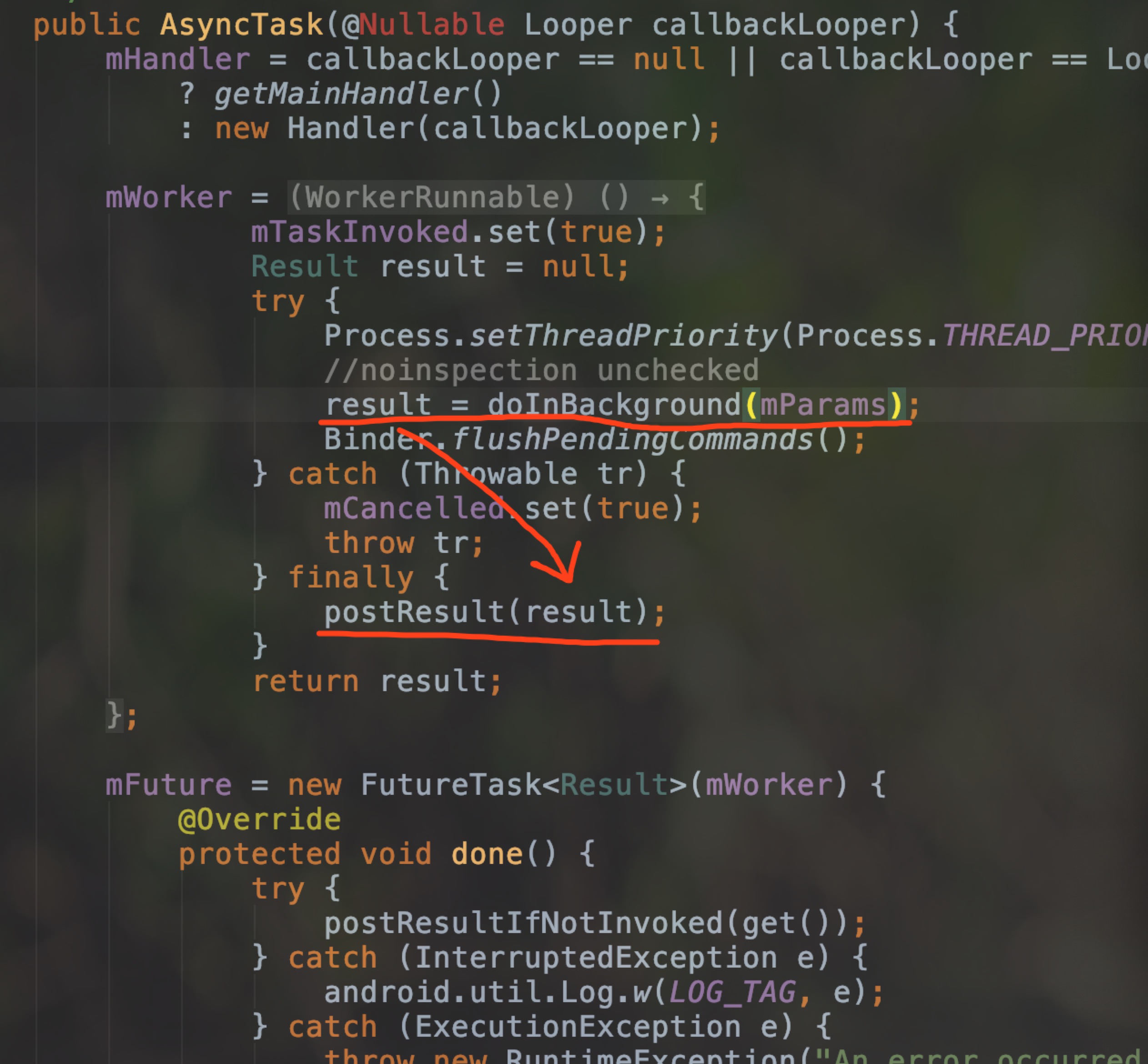
有了 result 之后调用 postResult(result)
private Result postResult(Result result) {
@SuppressWarnings("unchecked")
Message message = getHandler().obtainMessage(MESSAGE_POST_RESULT,
new AsyncTaskResult<Result>(this, result));
message.sendToTarget();
return result;
}
通过查看 postResult 这个方法的代码我们知道了其实是通过 handler 来实现线程的切换的.
通过查看 Handler 的初始化证明一下我们的结论.
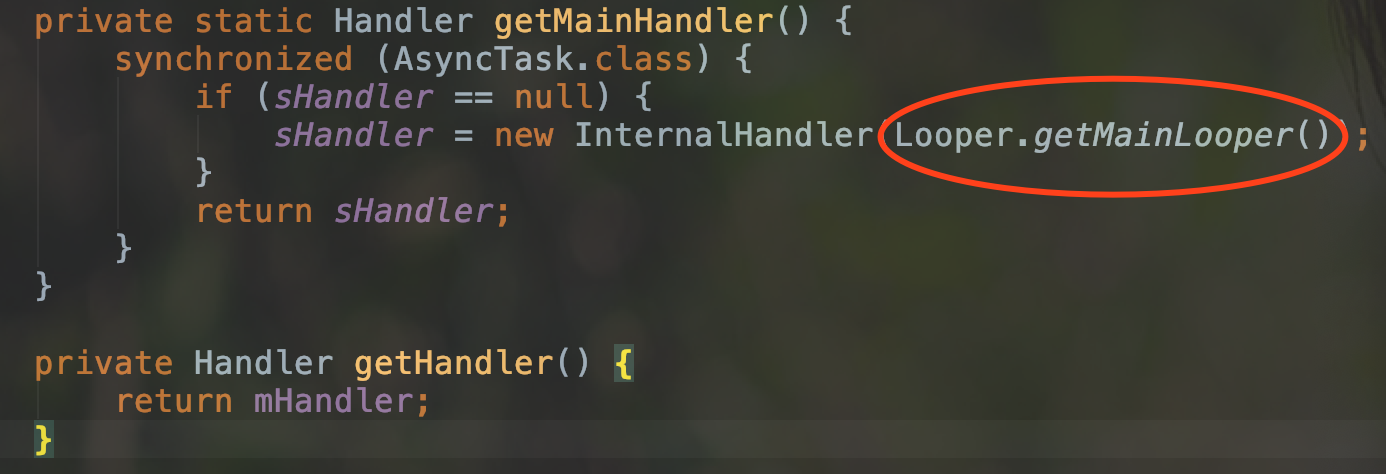
可以看到确实是通过 handler 实现了线程的切换.
如果你还不了解 handler 是怎么实现线程切换的.可以看看
好了至此呢,我们的 AsyncTask 源码就分析完了.我们来总结一下
总结 : AsyncTask 本质是线程池+handler 的方式来实现的.共用了两个线程池一个是SerialExecutor用来做任务的排队另一个是THREAD_POOL_EXECUTOR用来进行真正的执行. 3. Android中常用的四种线程池既然我们了解了 Android 中的线程池基本的东西了,不妨来看看 Android 中常用的四种线程池,它们都是基于 ThreadPoolExecutor 来创建的.
1. FixedThreadPoolpublic static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
通过分析它的创建呢我们就可以发现,它是个只有核心线程的线程池, 而且核心线程的数量是通过 nThreads 来指定的 , 并且线程在等待状态不会被回收 , 同时它的任务队列也没有大小的限制.
so 它能够更快的响应外界的请求.
2. CachedThreadPool public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
它是一个没有核心线程,并且非核心线程数量最大可以达到 Integer.MAX_VALUE 的线程池.
非核心线程的超时时长是60s,超过的就会被回收.
而 SynchronousQueue 是一个非常特殊的任务队列 , 可以理解为无法存储元素的队列.正因为如此,所以被加入得任务会立即得到执行.
因为当整个线程池都处于闲置状态且超过规定时间后,它的线程池中是没有线程存在的,所以它几乎是不占用任何系统资源的.
so 它适合执行大量耗时少的任务 .
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
它是一个核心线程数量固定,非核心线程可以非常大的线程池,并且超时时间为0,也就是说当非核心线程一旦将任务执行完毕,非核心线程就会立即被回收.
so 它适合执行定时任务和具有固定周期的重复任务.
4. SingleThreadExecutor public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
其实从名字上我们也能看出来,这是个只有一个核心线程的线程池.它能够确保所有任务都在同一线程中执行.
so 利用它可以不处理线程同步的问题.